Базы данных и геоинформационные системы. Атрибутивная информация
Целью настоящей статьи является ознакомление специалистов в области геодезии и картографии с механизмами хранения и обработки данных, которые предоставляют геоинформационные системы
А.В. Серов (ГУ «ТФИ РК», Сыктывкар)
Без правильной организации информации невозможно построение эффективно действующей ГИС. Хорошо подготовленная цифровая карта является основой любой ГИС, но и смысловая, атрибутивная информация играет важную роль в системах прикладного назначения. В ряде случаев она даже важнее картографической составляющей, например, в кадастровых системах.
Большинство современных программ, как ГИС, так и систем управления базами данных (СУБД), предоставляют интуитивно понятные, легкие в освоении инструменты для манипулирования данными. Однако для разработки информационной системы, содержащей две-три взаимосвязанных таблицы, уже требуется знание основ организации автоматизированного хранения информации.
Организация хранения информации, типы данных
Данные, которые могут быть сохранены в информационных системах, можно разделить на две основные категории:
элементарные (простые), например, число или строка;
составные (сложные), которые представляют собой определенным образом организованную совокупность простых.
Наиболее распространенными типами сложных данных являются массивы и записи.
Массив представляет собой упорядоченную последовательность простых данных одного типа чисел или строк. Каждому элементу массива присваивается порядковый номер индекс.
Запись представляет собой совокупность простых данных, как чисел, так и строк. Элементы записи принято называть ее полями, а совокупность записей, имеющих однотипные поля, файлом.
Файл является ничем иным, как массивом, состоящим из записей. Следовательно, каждой записи мы можем сопоставить индекс, который в этом случае принято именовать ключом записи. Очевидно, что каждому ключу в файле сопоставлена только одна запись и, наоборот, для каждой записи существует единственный ключ.
Можно вообразить бесконечное разнообразие типов сложных данных, массивов, состоящих из других массивов, записей, содержащих массивы в качестве полей, каждый элемент которых в свою очередь тоже является записью и т. п. Однако не все они имеют одинаковую практическую ценность с точки зрения последующей реализации в рамках вычислительных систем. Необходимо, чтобы вычисления проводились максимально быстро, а используемое программное обеспечение могло максимально гибко «настраиваться» для решения любых задач в различных прикладных областях. Эта идея приводит нас к понятию модели данных.
Модель данных представляет собой описание принципов, в соответствии с которыми осуществляются хранение и обработка данных. Поиск и выработка оптимальных моделей данных является уделом исследователей-математиков, работающих в области теории баз данных. В настоящее время в результате опытной реализации конкретных систем практическое применение нашли реляционная и объектно-ориентированная модели данных.
Модель данных в качестве составляющих содержит описания:
структуры данных, т. е. тех принципов, в соответствии с которыми осуществляется хранение и упорядочение данных;
методов манипулирования данными, т. е. тех принципов, в соответствии с которыми осуществляется создание новых данных путем обработки существующих;
принципов контроля целостности, т. е. формальных ограничений (правил), удостоверяющих соответствие данных той или иной предметной области.
Кратко рассмотрим реляционную модель данных, получившую наиболее широкое распространение.
Реляционная модель данных
Реляционная модель данных разработана в 1970 г. сотрудниками корпорации IBM. Она базируется на нескольких довольно простых принципах, в основе которых лежит понятие связи между различными атрибутами, отражающей отношения между сущностями и их атрибутами (характеристиками) в реальном мире.
Выберем какую-либо предметную область, в которой определены некоторые сущности, т. е. обособленные друг от друга элементы. Примерами сущностей являются «дерево», «дом», «день», «мысль» и т. п. Каждая сущность имеет тип, иными словами, есть правило, позволяющее находить похожие сущности, которые могут быть объединены в упорядоченную совокупность набор сущностей. Примерами наборов сущностей являются: «деревья», «дома», «месяц» (как совокупность «дней»), «цитатник» (как совокупность «мыслей»). Одна и та же сущность может принадлежать разным наборам. Например, сущность «дерево» может принадлежать наборам «деревья» и «лес», сущность «день» наборам «календарь» и «праздники».
Обособленность от других основной признак сущности. Обособленность означает, что существуют определенные атрибуты, посредством различения которых можно отделить один объект от другого. Примерами атрибутов являются «цвет», «наименование», «возраст» и т. п. Так, атрибутом сущности «дом» является его номер; каждый дом на одной улице имеет свой номер, что позволяет отличать дома друг от друга.
Запишем сказанное в символическом виде следующим образом: ДОМ(НОМЕР).
Пусть для некой сущности имеется набор атрибутов, который однозначно ее определяет. Такой набор называется ключом сущности. В общем случае число атрибутов в таком наборе больше одного. Например, знание только номера дома не позволит однозначно установить его местоположение, так как в городе на разных улицах много домов с одинаковыми номерами. Поэтому ключ сущности будет включать два атрибута «номер» и «улица»:
ДОМ(НОМЕР, УЛИЦА).
Между сущностями может существовать некоторая взаимосвязь, например, «дома» могут быть расположены в некотором «районе» или «городе». Рядом с «домом» может находиться «магазин» и т. п.
Подобно сущностям, связи могут иметь атрибуты и организовывать наборы. Это легко понять. Например, атрибутом связи «дом» «магазин» может быть расстояние между ними. Поблизости от дома может находиться несколько магазинов. В этом случае можно говорить о том, что связь образует набор «магазины поблизости от дома». Если же нас интересует только ближайший магазин, мы говорим о связи «магазин, ближайший к дому» (рис. 1).
Рис. 1. Наборы сущностей «дома» и «магазины» и наборы связей «магазины поблизости от дома», «магазин, ближайший к дому»
Магазины, ближайшие к дому, могут быть представлены как набор связей и как набор сущностей. Разделение этих способов организации данных в рамках реляционной модели достаточно условно.
Обратим внимание на число сущностей, которые образуют связь. В примере с магазинами и домом мы определили два набора связей, в один из которых может входить много магазинов (все ближайшие), в другой только один магазин (самый ближний).
Связь первого вида называется связью один-ко-многим (один дом много магазинов), второго вида один-к-одному (один дом один магазин).
Для формального графического отображения подобных ситуаций разработано специальное средство, именуемое ER-диаграммами, или диаграммами «сущность связь» (entity relationship). На рис. 2 показано, как на ER-диаграмме будет выглядеть пример с магазинами. Такие диаграммы исключительно важны при проектировании баз данных, так как позволяют в простой форме представить сложную структуру предметной области.
Рис. 2. ER-диаграмма связи сущностей «дом» и «магазин»; вид связи один-ко-многим
Говоря о сущностях, мы используем имена существительные: дом, магазин. Когда же упоминаем связи, то привлекаем глаголы расположен, находится. Это очень полезное правило, которое позволит начинающим легко формализовать предметную область в виде диаграмм «сущность связь».
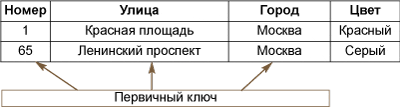
Наборы сущностей удобно представлять в табличном виде, где таблица олицетворяет набор сущностей, строки представляют сущности, а поля или колонки атрибуты сущностей. В заголовках полей таблицы содержатся наименования атрибутов сущности. На рис. 3 приведен пример таблицы для сущности ДОМ(НОМЕР, УЛИЦА, ГОРОД, ЦВЕТ).
Рис. 3. Пример таблицы для сущности ДОМ
Как отмечалось, в рамках модели объекты должны отличаться друг от друга. Посмотрим, какие из указанных в таблице на рис. 3 атрибутов позволят однозначно определить объект. Очевидно, что ни одно из полей, взятое отдельно, не поможет решить задачу, поскольку:
номера домов на разных улицах могут повторяться;
на каждой улице может быть несколько домов;
в городе много домов и улиц;
многие дома имеют одинаковый цвет.
Однако, если «отличать» один дом от другого используя значения первых трех полей в совокупности, задачу легко решить. В реляционной модели данных атрибут или совокупность атрибутов, посредством которой можно отождествить конкретный объект (единственный в таблице), носит название первичного ключа. Конечно, в базе данных может быть множество таблиц, содержащих те или иные сведения о сущности дом, однако хотя бы в одной из них первичный ключ должен существовать.
В базе данных может быть представлено несколько сущностей таблиц, между которыми определяются связи. Для наглядного представления строения базы данных в интересующей предметной области предназначена схема данных. Это подобное ER-диаграмме изображение, на котором указаны сущности и связи, а также атрибуты и ключи. Схема данных, в отличие от ER-диаграммы, отображает уже не логическую структуру связей между сущностями, а организацию данных в рамках системы управления базами данных программного средства, непосредственно осуществляющего хранение и манипулирование данными.
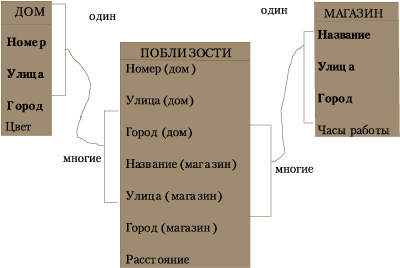
Построим схему базы данных, включающую сущности «дом», «магазин» и их связь (рис. 4).
Рис. 4. Пример схемы базы данных (жирным выделены атрибуты, входящие в первичный ключ)
С целью экономии площади рисунка в схеме данных принято изображать таблицу в виде одного столбца, заголовком которого является имя таблицы (сущности), а в строках расположены имена полей (атрибуты сущности).
На рис. 4 в базе данных существует таблица с заголовком ПОБЛИЗОСТИ. Для чего она нужна? Предположим, что установлена связь между таблицами ДОМ и МАГАЗИН. В общем случае каждый из магазинов расположен вблизи какого-нибудь дома и у каждого дома поблизости есть магазин. А это означает, что одному дому могут «соответствовать» несколько магазинов и, наоборот, каждому магазину несколько домов. Такой вид связи носит название многие-ко-многим и в большинстве «настольных» СУБД и ГИС функционально не реализован.
Чтобы организовать подобного рода связь в рамках реляционной модели при помощи связей один-ко-многим, приходится прибегать к специальному приему. Кроме того, дополнительная таблица позволяет хранить в базе данных важнейший атрибут связи расстояние. Таким образом, таблица ПОБЛИЗОСТИ является ничем иным, как набором связей.
Манипулирование данными
Раздел теории, который разрабатывает соответствующий математический аппарат, носит название реляционной алгебры.
Реляционная алгебра описывает правила осуществления над строками таблицы (которые еще называют кортежами) действий, именуемых операторами. В рамках школьной алгебры все знакомились с операторами сложения, вычитания, умножения и др. Аналогичные действия осуществляет и реляционная алгебра, с той лишь разницей, что операторы для работы с данными определены специфические, а операндами являются не числа, а целые таблицы. Результатом выполнения реляционных операторов также являются таблицы (путь даже не содержащие строк, т. е. пустые).
Рассмотрим важнейшие из реляционных операторов.
Выборка извлечение из таблицы строк, удовлетворяющих определенным условиям, накладываемым на значения полей (атрибутов).
Пример. Пусть дана сущность ДОМ(УЛИЦА, НОМЕР) , сведения о которой приведены в строках таблицы ДОМ. Нужно выбрать из таблицы только те строки, которые соответствуют домам, расположенным на улице «Геоинформационный проспект». Воспользовавшись оператором ВЫБОРКА, условно запишем выражение так: выбрать строки из таблицы ДОМ, где значение атрибута УЛИЦА равно «Геоинформационный проспект». Результатом выполнения оператора будет таблица
ДОМА_НА_ГЕОИНФОРМАЦИОННОЙ(УЛИЦА, НОМЕР).
Проекция извлечение из таблицы подмножества атрибутов. Например, отпала необходимость в использовании сведений о цвете домов. В этом случае можно создать новую таблицу без этого поля, но содержащую все другие поля и их значения в полном объеме.
Соединение построение одной таблицы из двух, основываясь на одинаковых значениях их одноименных полей. Допустим, мы имеем таблицы ДОМ и МАГАЗИН, при этом объекты из таблицы МАГАЗИНимеют атрибуты НАЗВАНИЕ, РАССТОЯНИЕ, НОМЕР ДОМА и УЛИЦА, где два последних (НОМЕР ДОМА и УЛИЦА) идентифицируют дом, до которого измерено расстояние. Необходимо построить таблицу, где будут отображены сведения о минимальных расстояниях от дома до магазина.
Запишем задачу при помощи операторов ВЫБОРКА и СОЕДИНЕНИЕ следующим образом: ВЫБРАТЬ строки из таблиц ДОМ и МАГАЗИН (в том числе строку из таблицы МАГАЗИН , содержащую минимальное значение РАССТОЯНИЯ, ГДЕ НОМЕР ДОМА из таблицы ДОМ равен НОМЕРУ ДОМА из таблицы МАГАЗИН и УЛИЦА из таблицы ДОМ совпадает с УЛИЦЕЙиз таблицы МАГАЗИН .
Результатом выполнения двух операторов будет таблица ДОМА_И_МАГАЗИНЫ(НОМЕР, УЛИЦА, МИНИМАЛЬНОЕ РАССТОЯНИЕ).
В реальности выполнение запросов возлагается на специальный программный продукт, называемый Системой управления базами данных (СУБД). Пользователю достаточно сформулировать запрос на специальном языке, который воспринимает СУБД, а затем все действия по составлению итоговой таблицы будут выполнены ею самостоятельно.
Язык SQL
Для создания таблиц и манипулирования данными в СУБД разработан язык SQL (Structured Query Language структурированный язык запросов). Он включает подмножества операторов, предназначенных для решения важнейших задач управления данными:
язык определения структуры базы данных предназначен для формирования таблиц;
язык манипулирования данными предназначен для выполнения запросов, подобных рассмотренным выше.
SQL содержит много разнообразных операторов и существует в нескольких видах (стандартах). Кратко рассмотрим важнейшие из операторов языка и запишем с его использованием приведенные ранее примеры.
Прежде всего остановимся на полях таблиц атрибутах. Уже упоминалось, что атрибут может быть строкой или числом, т. е. иметь определенный тип, указывающий, в какой форме должно быть представлено значение атрибута. Для указания типа поля таблицы в SQL используются обозначения: CHAR(n) строка длиной N символов, INTEGER целое число, FLOAT действительное число.
Например, НОМЕР ДОМА может иметь тип FLOAT, а НАЗВАНИЕ УЛИЦЫ тип CHAR(100). SQL определяет множество подобных описаний типов атрибутов, которые вместе именуются типами данных.
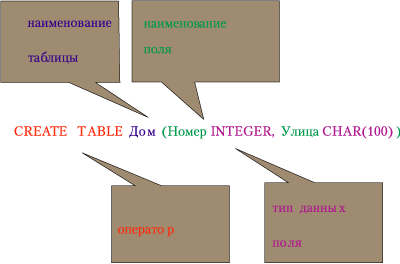
Для создания таблиц используется оператор CREATE TABLE (создать таблицу). Вид оператора для таблицы Дом приведен на рис. 5.
Рис. 5. Пример оператора CREATE TABLE
Для выполнения выборки используется оператор SELECT FROM WHERE GROUP BY (выбрать из где группировать). Этот наиболее часто применяемый оператор языка SQL состоит из четырех основных частей. После слова SELECT следует перечень полей, которые необходимо выбрать. Тут же могут быть указаны функции, вычисляющие значения выбранных полей. Например, функция SUM (имя поля) определяет сумму значений полей, по которым осуществляется группировка, а функция MIN (имя поля) минимальное значение среди них. После FROM следуют имена таблиц, участвующих в запросе, после WHERE условия, которым должны удовлетворять данные в исходных таблицах, чтобы попасть в результат запроса. Условие может включать в себя одно или несколько имен полей и логические операторы (больше, меньше, равно и др.). И, наконец, после фразы GROUP BY следует имя поля, по которому должны быть сгруппированы результаты. Если после SELECT указаны функции, вычисляющие значения полей, то сами поля должны быть указаны в GROUP BY. Строки исходной таблицы, в которых значения этих полей одинаковы, будут рассматриваться как одна строка в результирующей таблице.
Язык оператора SELECT во многом похож на естественную речь, посредством которой мы записывали примеры работы реляционного оператора выборки. Переведем теперь их на язык SQL.
Построим при помощи запроса SELECT таблицу ДОМА_НА_ГЕОИНФОРМАЦИОННОЙ. Вид запроса приведен на рис. 6.
Рис. 6. Пример оператора SELECT
Как видно из рис. 6, мы просто заменили в тексте выборки русские слова на английские эквиваленты. Теперь решим более сложную задачу с составлением перечня домов и указанием ближайших к ним магазинов.
Выборка будет выглядеть так: SELECT НОМЕР, УЛИЦА, MIN(РАССТОЯНИЕ) FROM ДОМ, МАГАЗИН WHERE ДОМ.УЛИЦА = МАГАЗИН.УЛИЦА AND ДОМ.НОМЕР = МАГАЗИН.НОМЕР GROUP BY ДОМ.НОМЕР, ДОМ.УЛИЦА.
Точка между именами таблиц и полей используется для того, чтобы СУБД могла определить, какой именно таблице принадлежат поля. Это необходимо, потому что в таблицах ДОМ и МАГАЗИН есть поля с одинаковыми именами.
Результаты запроса могут быть помещены в таблицу ДОМА_И_МАГАЗИНЫ(НОМЕР, УЛИЦА, МИНИМАЛЬНОЕ РАССТОЯНИЕ) , в которой нет иных сведений о магазинах, кроме вычисленного запросом минимального расстояния. Если бы в SELECT не была включена фраза GROUP BY, то результирующей стала таблица ДОМА_И_ВСЕ МАГАЗИНЫ(НОМЕР, УЛИЦА, РАССТОЯНИЕ) , где было бы по одной строке для каждого магазина. СУБД вычисляла минимальные расстояния поэтапно: сначала построила таблицу ДОМА_И_ВСЕ МАГАЗИНЫ, а затем сделала выборку и поместила результат в итоговую таблицу ДОМА_И_МАГАЗИНЫ.
Неявным образом мы создали СОЕДИНЕНИЕ между таблицами ДОМ и МАГАЗИН. В языке SQL для этих целей существует оператор JOIN (соединение), но простейшие соединения таблиц можно осуществлять в рамках оператора SELECT описанным выше способом.
При рассмотрении особенностей хранения пространственных данных мы еще вернемся к описанию языка SQL, чтобы рассмотреть новые типы данных и операторы, которые могут быть к ним применены.






 Без правильной организации информации невозможно построение эффективно действующей ГИС. Хорошо подготовленная цифровая карта является основой любой ГИС, но и смысловая, атрибутивная информация играет важную роль в системах прикладного назначения. В ряде случаев она даже важнее картографической составляющей, например, в кадастровых системах.
Без правильной организации информации невозможно построение эффективно действующей ГИС. Хорошо подготовленная цифровая карта является основой любой ГИС, но и смысловая, атрибутивная информация играет важную роль в системах прикладного назначения. В ряде случаев она даже важнее картографической составляющей, например, в кадастровых системах.